搜索到
19
篇与
的结果
-
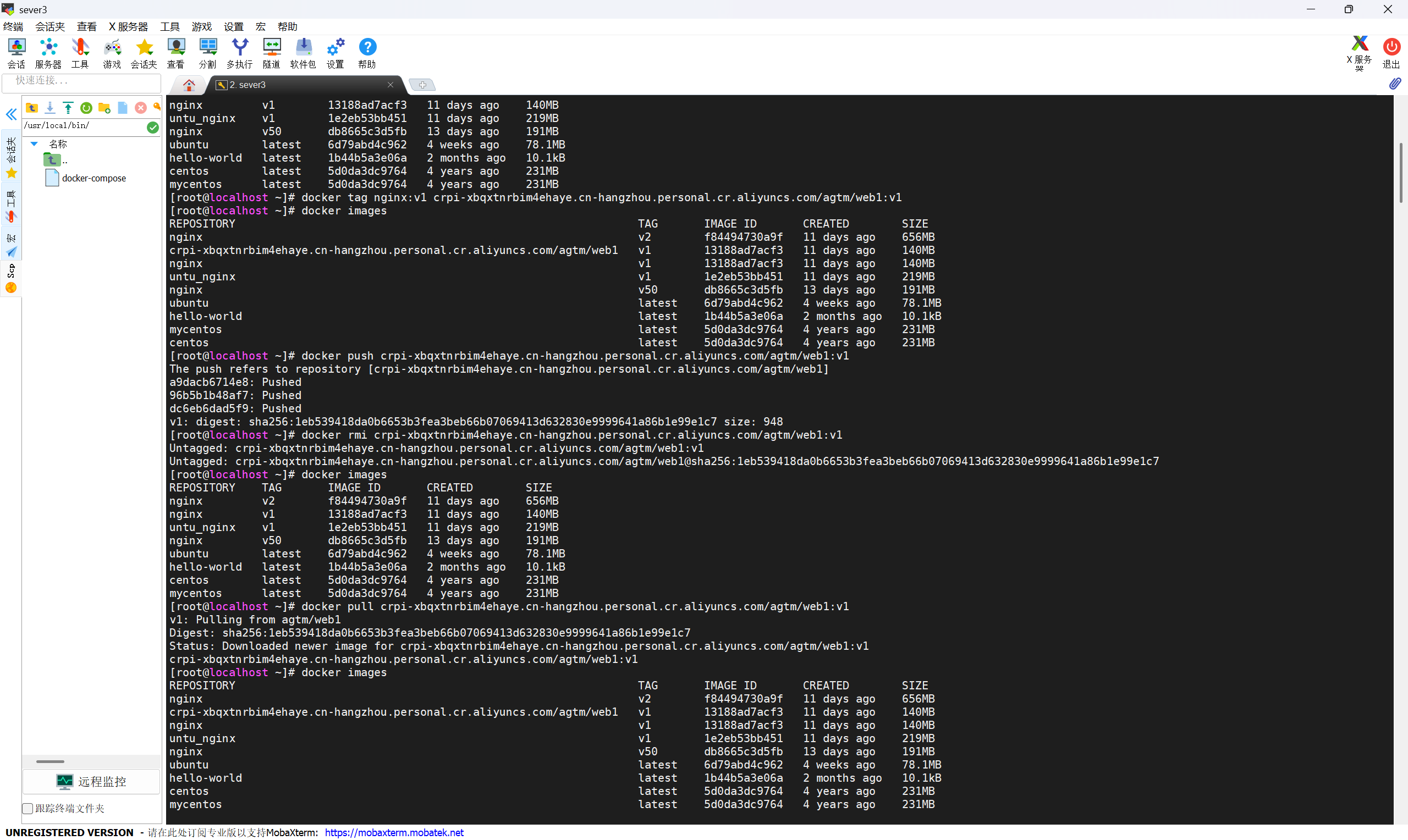
 Docker仓库管理 阿里云仓库登录阿里云 Container Registry$ docker login --username=bbj1030 registry.cn-hangzhou.aliyuncs.com用于登录的用户名为阿里云账号全名,密码为开通服务时设置的密码。您可以在访问凭证页面修改凭证密码。注意:使用 RAM 用户(子账号)登录镜像仓库时,不支持企业别名带有英文半角句号(.)。从Registry中拉取镜像$ docker pull registry.cn-hangzhou.aliyuncs.com/bbj1030/web:[镜像版本号]将镜像推送到Registry$ docker login --username=bbj1030 registry.cn-hangzhou.aliyuncs.com$ docker tag [ImageId] registry.cn-hangzhou.aliyuncs.com/bbj1030/web:[镜像版本号]$ docker push registry.cn-hangzhou.aliyuncs.com/bbj1030/web:[镜像版本号]请根据实际镜像信息替换示例中的[ImageId]和[镜像版本号]参数。选择合适的镜像仓库地址从ECS推送镜像时,可以选择使用镜像仓库内网地址。推送速度将得到提升并且将不会损耗您的公网流量。如果您使用的机器位于VPC网络,请使用 registry-vpc.cn-hangzhou.aliyuncs.com 作为Registry的域名登录。示例使用"docker tag"命令重命名镜像,并将它通过专有网络地址推送至Registry。$ docker imagesREPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZEregistry.aliyuncs.com/acs/agent 0.7-dfb6816 37bb9c63c8b2 7 days ago 37.89 MB$ docker tag 37bb9c63c8b2 registry-vpc.cn-hangzhou.aliyuncs.com/acs/agent:0.7-dfb6816使用 "docker push" 命令将该镜像推送至远程。$ docker push registry-vpc.cn-hangzhou.aliyuncs.com/acs/agent:0.7-dfb6816私有仓库Docker Register[root@server1 install]# ./install_registry.sh[root@server1 install]# docker psCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES962c643215c8 registry "/entrypoint.sh /etc…" 5 minutes ago Up 5 minutes 0.0.0.0:5000->5000/tcp, [::]:5000->5000/tcp registry[root@server1 install]# docker login localhost:5000Username: adminPassword: Login Succeeded[root@server1 install]# docker tag nginx:v1 localhost:5000/nginx:v1[root@server1 install]# docker push localhost:5000/nginx:v1The push refers to repository [localhost:5000/nginx]68814fc317a7: Pushed dc6eb6dad5f9: Pushed v1: digest: sha256:c6d331c815ef6717b60a4a7c631bda85506eb77f47b159ef44fdbbe308957753 size: 741[root@server1 install]# docker rmi localhost:5000/nginx:v1Untagged: localhost:5000/nginx:v1Untagged: localhost:5000/nginx@sha256:c6d331c815ef6717b60a4a7c631bda85506eb77f47b159ef44fdbbe308957753[root@server1 install]# docker pull localhost:5000/nginx:v1v1: Pulling from nginxDigest: sha256:c6d331c815ef6717b60a4a7c631bda85506eb77f47b159ef44fdbbe308957753Status: Downloaded newer image for localhost:5000/nginx:v1localhost:5000/nginx:v1[root@server1 install]# docker imagesREPOSITORY TAG IMAGE ID CREATED SIZElocalhost:5000/nginx v1 890316d09026 4 days ago 140MB企业级仓库Docker harbor[root@server1 harbor]# cat harbor.ymlhostname: 192.168.80.10http: port: 80harbor_admin_password: Harbor12345
Docker仓库管理 阿里云仓库登录阿里云 Container Registry$ docker login --username=bbj1030 registry.cn-hangzhou.aliyuncs.com用于登录的用户名为阿里云账号全名,密码为开通服务时设置的密码。您可以在访问凭证页面修改凭证密码。注意:使用 RAM 用户(子账号)登录镜像仓库时,不支持企业别名带有英文半角句号(.)。从Registry中拉取镜像$ docker pull registry.cn-hangzhou.aliyuncs.com/bbj1030/web:[镜像版本号]将镜像推送到Registry$ docker login --username=bbj1030 registry.cn-hangzhou.aliyuncs.com$ docker tag [ImageId] registry.cn-hangzhou.aliyuncs.com/bbj1030/web:[镜像版本号]$ docker push registry.cn-hangzhou.aliyuncs.com/bbj1030/web:[镜像版本号]请根据实际镜像信息替换示例中的[ImageId]和[镜像版本号]参数。选择合适的镜像仓库地址从ECS推送镜像时,可以选择使用镜像仓库内网地址。推送速度将得到提升并且将不会损耗您的公网流量。如果您使用的机器位于VPC网络,请使用 registry-vpc.cn-hangzhou.aliyuncs.com 作为Registry的域名登录。示例使用"docker tag"命令重命名镜像,并将它通过专有网络地址推送至Registry。$ docker imagesREPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZEregistry.aliyuncs.com/acs/agent 0.7-dfb6816 37bb9c63c8b2 7 days ago 37.89 MB$ docker tag 37bb9c63c8b2 registry-vpc.cn-hangzhou.aliyuncs.com/acs/agent:0.7-dfb6816使用 "docker push" 命令将该镜像推送至远程。$ docker push registry-vpc.cn-hangzhou.aliyuncs.com/acs/agent:0.7-dfb6816私有仓库Docker Register[root@server1 install]# ./install_registry.sh[root@server1 install]# docker psCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES962c643215c8 registry "/entrypoint.sh /etc…" 5 minutes ago Up 5 minutes 0.0.0.0:5000->5000/tcp, [::]:5000->5000/tcp registry[root@server1 install]# docker login localhost:5000Username: adminPassword: Login Succeeded[root@server1 install]# docker tag nginx:v1 localhost:5000/nginx:v1[root@server1 install]# docker push localhost:5000/nginx:v1The push refers to repository [localhost:5000/nginx]68814fc317a7: Pushed dc6eb6dad5f9: Pushed v1: digest: sha256:c6d331c815ef6717b60a4a7c631bda85506eb77f47b159ef44fdbbe308957753 size: 741[root@server1 install]# docker rmi localhost:5000/nginx:v1Untagged: localhost:5000/nginx:v1Untagged: localhost:5000/nginx@sha256:c6d331c815ef6717b60a4a7c631bda85506eb77f47b159ef44fdbbe308957753[root@server1 install]# docker pull localhost:5000/nginx:v1v1: Pulling from nginxDigest: sha256:c6d331c815ef6717b60a4a7c631bda85506eb77f47b159ef44fdbbe308957753Status: Downloaded newer image for localhost:5000/nginx:v1localhost:5000/nginx:v1[root@server1 install]# docker imagesREPOSITORY TAG IMAGE ID CREATED SIZElocalhost:5000/nginx v1 890316d09026 4 days ago 140MB企业级仓库Docker harbor[root@server1 harbor]# cat harbor.ymlhostname: 192.168.80.10http: port: 80harbor_admin_password: Harbor12345 -
prometheus各组件的简单了解 1.Prometheus Server:负责数据采集、存储和查询数据采集 (Pull):定期从配置好的目标(Targets)上拉取指标数据。数据存储 (Store):将采集到的数据以时间序列(Time-Series)的形式存储在本地磁盘。数据查询 (Query):提供一个 HTTP API 接口,允许你使用 PromQL 语言查询存储的数据。Client Libraries (客户端库)如果你想监控自己写的应用程序,就需要使用客户端库。库会在你的应用程序中启动一个 HTTP 服务,并在 /metrics 路径下暴露所有定义好的指标。Exporters (导出器)对于无法直接集成客户端库的现成软件(如数据库、消息队列、操作系统),Exporters 是最佳选择。一个独立运行的进程,它会去查询目标软件的状态(比如通过 SSH、API 或读取日志),然后将这些状态转换为 Prometheus 能理解的格式,并在 /metrics 路径下暴露出来。Pushgateway (推送网关)标准的 “拉取” 模式对长时间运行的服务很友好,但对于一些短生命周期的任务就不适用了,因为任务结束后,Prometheus 可能还没来得及去拉取数据。提供一个中间网关。短任务可以主动将自己的指标 “推” 到 Pushgateway,然后由 Prometheus Server 从 Pushgateway 拉取数据。Alertmanager (告警管理器)光有数据和图表还不够,关键是能在异常时及时通知到人。接收告警:从 Prometheus Server 接收告警信息。处理告警:对告警进行分组(如将同一服务的多个告警合并)、抑制(如一个高级别告警触发后,抑制其引发的低级别告警)、路由(根据告警级别或标签发送到不同的通知渠道)。发送通知:通过 Email、PagerDuty、Slack、Webhook(可对接钉钉、企业微信)等方式发送告警通知。PromQL (查询语言)这是 Prometheus 的灵魂,让你能从海量数据中挖掘价值。avg without(cpu,mode) (rate(node_cpu_seconds_total {mode="idle"} [1m]))node_cpu_seconds_total {mode="idle"}选择指标 node_cpu_seconds_total(节点 CPU 累计使用时间) 筛选条件 mode="idle" 表示只关注 CPU 的空闲状态rate(... [1m])计算 1 分钟时间窗口内的每秒平均增长率这里实际上是计算 CPU 处于空闲状态的每秒平均时间avg without(cpu,mode)对结果进行平均值计算without(cpu,mode) 表示在计算平均值时,排除 cpu(CPU 核心编号)和 mode(这里固定为 idle)这两个标签这意味着会将同一节点的所有 CPU 核心的空闲率进行平均,得到整个节点的平均 CPU 空闲率指标类型Counter计数器:只增不减Gauge仪表盘:可增可减Histogram直方图:可以分别求出各个数据段的分布Summary摘要:可以相较于直方图增加一个频率分布部署时需要注意的问题Prometheus前台启动以后,后面改为systemd管理,需要将前台启动的进程关闭,否则你后面启动的并没有真正运行如果你在web页面不能够看到对应的endpoint,那么就是你修改的配置文件没有生效node_exporter、mysqld_exporter没有使用systemd管理mysqld_exporter部署以后大家要检查指标是否正常
-
shell脚本以及三剑客的简单回顾与应用 单引号'':会让内部的一些特殊符号失效双引号"":可以让内部的变量正常使用[root@server1 ~]# a=1 && (a=2;echo "子shell中a=$a") && echo "子shell外a=$a"子shell中a=2子shell外a=1score=80[ $score -ge 90 ] && echo "获得三好学生荣誉"[ $score -ge 90 ] || echo "没有获得三好学生荣誉"grep作用:过滤文本内容选项 描述-E :--extended--regexp 模式是扩展正则表达式(ERE)-i :--ignore--case 忽略大小写-n: --line--number 打印行号-o:--only--matching 只打印匹配的内容-c:--count 只打印每个文件匹配的行数-B:--before--context=NUM 打印匹配的前几行-A:--after--context=NUM 打印匹配的后几行-C:--context=NUM 打印匹配的前后几行--color[=WHEN] 匹配的字体颜色,别名已定义了-v:--invert--match 打印不匹配的行-e 多点操作eg:grep -e "^s" -e "s$"通过正则表达式grep出IP地址ifconfig ens160 | grep inet | grep -E '.' | grep -oE '([[:digit:]]{1,3}.){3}[[:digit:]]{1,3}' | head -1sed常见参数:‐n :只打印模式匹配的行‐e :直接在命令行模式上进行sed动作编辑,此为默认选项‐f :将sed的动作写在一个文件内,用–f filename 执行filename内的sed动作‐r :支持扩展表达式‐i :直接修改文件内容通过sed替换掉IP地址前后的内容ifconfig | sed -n '/netmask/p' | sed 's/^.inet //g' | sed 's/ netmask.$//g' | sed -n '1p'通过sed -i替换修改文件里的内容sed 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config -iawk-F:指定分隔符 -f:指定文件 常用 awk 内置变量变量名 属性$0 当前记录$1~$n 当前记录的第n个字段FS 输入字段分割符 默认是空格RS 输入记录分割符 默认为换行符NF 当前记录中的字段个数,就是有多少列NR 已经读出的记录数,就是行号,从1开始OFS 输出字段分割符 默认也是空格ORS 输出的记录分割符 默认为换行符通过awk对竖着的内容进行累加求和,之后可以用于其他分析工作awk 'BEGIN{sum=0;count=0} {if ($2=="shuxue"){count++;sum+=$3}} END{avg=sum/count;print "avg: " avg}' testfile使用awk数组,用字段的名字作为数组的索引,对应的数值为该字段出现的次数netstat -an | awk '/^tcp/{++s[$6]} END{for (a in s) print a,s[a]}'运行脚本的方式给脚本x权限,并通过文件路径的方式运行脚本 直接运行解释器,将脚本作为解释器的参数 退出状态码0-255在脚本结束的时候可以通过exit关键字指定退出状态码 可以通过$?来查询退出状态码 只读变量readonly 变量 删除变量unset 变量 位置变量$0:脚本名 $1,$2....:第一个、第二个参数 $#:参数个数 $*:所有参数 $@:所有参数,但可以迭代一次取出每个参数 字符串拼接name2="black"str3="hello, "${name2}str4="hello, ${name2}"字符串长度echo ${#text}字符串截取echo ${#text:2:2}创建数组array_name=(value1 value2 value3 ...)array_name=([0]=value1 [1]=value2 ...)获取数组的元素[root@server1 ~]# echo "First fruit: ${fruits[0]}"First fruit: apple[root@server1 ~]# echo "First fruit: ${fruits[@]}"First fruit: apple banana orange[root@server1 ~]# echo ${nums[*]}nls 18 teacher获取元素的个数[root@server1 ~]# echo ${#nums[*]}3[root@server1 ~]# echo ${#nums[@]}3删除元素[root@server1 ~]# unset nums[0][root@server1 ~]# echo ${nums[@]}18 teacher[root@server1 ~]# echo ${nums[0]}[root@server1 ~]# echo ${nums[1]}18[root@server1 ~]# echo ${nums[2]}teacher[root@server1 ~]# echo ${#nums[@]}2数学计算[root@server1 ~]# x=1[root@server1 ~]# y=2[root@server1 ~]# z=expr ${x} + ${y}[root@server1 ~]# echo $z3[root@server1 ~]# x=2[root@server1 ~]# y=3[root@server1 ~]# z=$[$x + $y][root@server1 ~]# echo $z5$((num1 + num2))let sum+=$i数值判断-eq:等于-ne:不等于-gt:大于-lt:小于-ge:大于等于-le:小于等于将命令的执行结果赋值给变量val=expr ${x} + ${y}userid1=$(awk -F: '{if (NR==10) print $3}' /etc/passwd)用户交互read常用选项选项 描述-p 在读取输入之前显示提示信息-n 限制输入的字符数-s 隐藏用户输入-a 将输入存储到数组变量中-d 指定用于终止输入的分隔符-t 设置超时时间(以秒为单位)-e 允许使用 Readline 编辑键-i 设置默认值for循环的用法[root@server1 ~]# for i in {1..5};do echo $i;done[root@server1 ~]# for ((i=0;i<10;i++))do echo $i;done当条件不成立的时候结束循环while 条件do...done当条件成立的时候结束循环until 条件do...donebreak:结束while、until、for循环continue:结束循环中的某一轮定义函数function FUNNAME(){函数体返回值}FUNNME #调用函数$- 输出的 himBHs 是当前 Shell 启用的选项标志组合,每个字母对应一项具体功能,含义如下:h:启用哈希表(hashall) Shell 会将执行过的命令路径缓存到哈希表中,再次执行时无需重新搜索 $PATH,加速命令查找。 i:交互式 Shell(interactive) 表示当前 Shell 是交互式的(如终端直接输入命令的环境),而非脚本运行的非交互式环境。 交互式 Shell 会提供命令行提示符、历史记录等功能。 m:启用作业控制(monitor) 允许使用 & 后台运行进程,以及 fg/bg/jobs 等命令管理前台 / 后台作业。 B:启用花括号扩展(brace expansion) 支持类似 a{1,2,3} 扩展为 a1 a2 a3、{1..5} 扩展为 1 2 3 4 5 的语法。 H:启用历史扩展(history expansion) 允许使用 ! 相关语法调用历史命令,例如 !! 重复上一条命令,!n 执行历史记录中第 n 条命令。 s:从标准输入读取命令(stdin) 通常在非交互式 Shell 中启用(如通过管道传递命令时),表示 Shell 会从标准输入而非脚本文件读取命令执行。
-
主从复制 主从复制的应用场景读写分离架构原理:主节点负责处理所有写操作(插入、更新、删除)和核心读操作,从节点仅处理非核心读操作(如查询、统计)。优势:分散读压力,避免单节点因大量读请求而性能瓶颈;主从节点可独立优化(如主节点侧重写性能,从节点增加缓存提升读速度)。数据备份与灾备实时备份:从节点同步主节点数据,可作为 “热备份”,避免主节点故障导致数据丢失。离线备份:从节点可单独执行备份操作(如定时生成快照),不影响主节点的正常业务。跨介质备份:主节点数据存储在高性能存储(如 SSD),从节点可将数据备份到低成本存储(如 HDD),平衡成本与安全性。 故障转移与高可用主节点故障时,将从节点提升为新主节点,保证服务连续性部署多个从节点,即使部分从节点故障,仍有其他节点可用,降低单点故障风险数据分析主节点专注于线上业务(如用户交易),从节点用于离线数据分析(如用户行为统计、报表生成),避免分析任务占用主节点资源跨地域部署与延迟优化在不同地域部署从节点,用户访问时连接本地从节点,减少跨地域网络延迟全量复制的详细流程从节点发起同步请求从节点启动后,会向主节点发送 PSYNC ? -1 命令:? 表示从节点不知道主节点的运行 ID(runID); -1 表示从节点没有保存有效的复制偏移量(offset);主节点收到后,会返回 FULLRESYNC 响应,其中 runID 是主节点的唯一标识,offset 是主节点当前的写偏移量主节点生成 RDB 快照主节点执行 BGSAVE 命令,在后台异步生成 RDB 快照文件:生成期间,主节点会继续处理客户端的写命令(这些命令会被临时存入复制缓冲区);若 BGSAVE 失败(如内存不足),主节点会拒绝从节点的同步请求。主节点发送 RDB 文件主节点通过网络将 RDB 文件发送给从节点,发送过程中会持续记录新的写命令到复制缓冲区;若网络中断,从节点会重新发起同步,可能再次触发全量复制(取决于中断时间)。从节点加载 RDB 并执行缓冲命令从节点接收完 RDB 文件后,会先清空自身数据库(避免数据冲突);加载 RDB 文件到内存,恢复主节点在生成快照时的状态;加载完成后,从节点会执行主节点在 RDB 生成期间存入复制缓冲区的所有写命令,最终与主节点的偏移量保持一致。增量复制的详细流程从节点重连并发起增量同步请求当从节点与主节点短暂断开后重新连接时,会发送 PSYNC <master_runid> <slave_offset> 命令:<master_runid>:从节点记录的上次连接的主节点运行 ID(唯一标识主节点)。<slave_offset>:从节点当前的复制偏移量(表示已同步到的位置)。主节点验证同步条件运行 ID 验证:确认从节点提供的 master_runid 与自身一致(确保未更换主节点)。偏移量验证:检查从节点的 slave_offset 是否在复制积压缓冲区的范围内(即缓冲区中是否包含从该偏移量之后的所有命令)。主节点响应并发送增量数据若上述验证通过,主节点返回 CONTINUE 响应,告知从节点可以进行增量同步。主节点从复制积压缓冲区中,提取从 slave_offset 之后的所有命令,发送给从节点。从节点执行命令并同步状态从节点接收并执行这些增量命令,更新自身数据。执行完成后,从节点的偏移量与主节点保持一致,恢复正常同步状态。slave-serve-stale-data yes当从节点与主节点的连接中断(如网络故障),且无法进行增量或全量复制时:若配置为 yes(默认):从节点会继续响应客户端的读请求,返回当前已有的数据(可能已过时,与主节点不一致); 若配置为 no:从节点会拒绝所有读请求,返回 SYNC with master in progress 错误。 主节点重点指标INFO server:redis_version:6.2.19 # Redis 服务器的版本号 uptime_in_seconds:14339 # 服务器启动至今的运行时间(单位:秒)INFO replication:role:master # 当前节点的角色(master 表示为主节点) connected_slaves:1 # 已连接的从节点数量 master_repl_offset:1000000 # 主节点的复制偏移量(记录已写入数据的字节位置,用于主从同步) repl_backlog_size:10485760 # 复制积压缓冲区的大小(10485760 字节 = 10MB,用于从节点重连时快速同步) repl_backlog_ttl:3600 # 复制积压缓冲区的存活时间(单位:秒,若从节点断开超过此时长,缓冲区将被释放)INFO stats:total_commands_processed:1000000 # 服务器启动至今累计处理的命令总数 instantaneous_ops_per_sec:1000 # 当前每秒处理的命令数(即 QPS,反映实时性能负载)INFO memory:used_memory_human:100.00M # 已使用的内存量(人性化显示,此处为 100MB)从节点重点指标INFO server:redis_version:6.2.19 # Redis 服务器的版本号 uptime_in_seconds:14339 # 服务器启动至今的运行时间(单位:秒)INFO replication:role:slave # 当前节点的角色(slave 表示为从节点) master_host:192.168.1.100 # 关联的主节点 IP 地址 master_port:6379 # 关联的主节点端口号 master_link_status:up # 主从连接状态(up 表示连接正常,down 表示连接断开) master_last_io_seconds_ago:0 # 最后一次与主节点进行通信的时间间隔(单位:秒,0 表示刚刚通信过) master_sync_in_progress:0 # 是否正在与主节点同步数据(0 表示未同步,1 表示正在同步) lag = master_repl_offset - slave_repl_offset # 主从同步延迟(主节点偏移量减去从节点偏移量) slave_repl_offset:1000000 # 从节点的复制偏移量(记录已同步主节点数据的字节位置) slave_priority:100 # 从节点在哨兵模式下的故障转移优先级(值越小优先级越高)
-
mysql备份 备份种类冷备份数据库状态:备份时数据库完全关闭(离线状态),不接受任何用户访问(读 / 写均被禁止)。适用场景:非核心业务系统,可接受长时间停机(如夜间维护窗口)。数据量较小,备份耗时短的场景。对备份一致性要求极高(离线状态下数据无变动,天然一致)。温备份数据库状态:备份时数据库运行,但仅允许读操作,禁止写操作(或写操作被阻塞 / 延迟)。适用场景:可接受短时间写操作中断的业务(如中小型网站的非高峰时段)。数据量中等,备份耗时可控(通常几分钟到几十分钟)。热备份数据库状态:备份时数据库正常运行,允许同时进行读和写操作,几乎不影响业务。适用场景:核心业务系统(如电商、金融),要求 7x24 小时不间断运行。数据量大,无法接受停机或写阻塞的场景。实际生产中,常结合多种备份方式(如热备份 + 定期冷备份)提高数据安全性。逻辑备份基于数据的逻辑结构(如表、记录、字段)进行备份,通过应用程序(如数据库客户端)提取数据并转换为通用格式(如 SQL 语句、CSV 文件),备份的是 “可读的逻辑内容”。物理备份直接对存储数据的物理介质(如磁盘、分区、文件系统)进行复制,备份的是数据的原始二进制形式,不依赖数据库或应用程序的逻辑结构。全量备份指完整备份整个数据集,即一次性复制目标系统中所有需要备份的数据(如整个数据库、文件夹或磁盘),无论数据是否发生过变化。增量备份指仅备份自上一次备份(可以是全量或增量备份)后发生变化的数据,不重复备份未修改的内容。例如:周一做全量备份,周二仅备份周一到周二新增或修改的文件,周三仅备份周二到周三变化的文件。musqldump命令参数 解释 -B:可以同时接多个库名,备份多个库 -A:备份所有的数据库 --triggers:默认启用,除非使用 --skip-triggers,否则触发器会自动备份 -R:用于备份数据库中的存储过程和存储函数,默认情况下,mysqldump 不会备份存储过程和函数。 -F:刷新binlog,在定期备份场景中(如每日全量备份),使每次备份对应一个新的二进制日志起点 -d:用于仅备份数据库的表结构(schema),不包含表中的实际数据 -t:用于仅备份数据库表中的数据(记录),不包含表结构(schema) -x:是在备份过程中对所有数据库的所有表施加读锁(READ LOCAL),以保证备份数据的一致性 备份 MyISAM 等不支持事务的存储引擎,若备份时不锁定表,可能导致备份数据不完整 --single-transaction:快照备份 mysqldump 会先启动一个事务(START TRANSACTION WITH CONSISTENT SNAPSHOT),基于 InnoDB 的多版 本并发控制(MVCC)机制,创建一个数据的一致性快照 备份过程中,所有操作都基于这个快照进行,即使其他会话修改了数据,也不会影响备份内容,确保备份文件是 一个 “时间点一致” 的数据副本 备份期间不锁定表,其他会话可以正常执行读写操作(INSERT、UPDATE、DELETE 等),对业务影响极小 备份 InnoDB 存储引擎的表,这是最主要的场景。InnoDB 支持事务和 MVCC,--single-transaction 能完美利用 这些特性实现 “热备份”(不中断业务) --master-data:会记录备份时的二进制日志位置,且都会自动触发日志刷新(相当于-F选项),确保日志起点的准确性 --master-data=1:生成未注释的 CHANGE MASTER TO 命令 --master-data=2:生成注释掉的 CHANGE MASTER TO 命令,更常用,因为它仅记录信息而不改变数据库状态 备份所有数据库[root@server1 ~]# mysqldump -uroot -p123456 -A > /backup/full.sql备份单个库[root@server1 ~]# mysqldump -uroot -p123456 test > /backup/test.sql备份单个表[root@server1 ~]# mysqldump -uroot -p123456 world city > /backup/city.sql备份多个库[root@server1 ~]# mysqldump -uroot -p123456 -B db01 db02 > /backup/db01_db02.sql使用gzip压缩备份数据[root@server1 ~]# mysqldump -B test | gzip> test_db_bak.sql.gz备份多个表mysqldump 数据库名 表名1 表名2 … > 备份文件名常用全量热备份语句[root@server1 ~]# mysqldump -uroot -p123456 -A -R --triggers --master-data=2 --single-transaction |gzip > /tmp/full_$(date +%F).sql.gzXtrabackup安装安装 Percona 仓库yum install -y https://repo.percona.com/yum/percona-release-latest.noarch.rpm启用相关仓库percona-release enable-only tools release安装适合当前系统的 xtrabackupyum install -y percona-xtrabackup-24Xtrabackup:热备支持 对 InnoDB 表:备份时无需锁表(FLUSH TABLES WITH READ LOCK仅在备份非 InnoDB 表时短暂生效), 不影响业务读写,属于真正的热备。 对 MyISAM/CSV 等非事务表:仍需加读锁(温备),但锁表时间极短(仅复制表文件的瞬间), 相比原生cp命令锁表备份更友好。 全量备份[root@db01 ~]# innobackupex --user=root --password=123 --no-timestamp /backup/full重新准备一下文件[root@db01 full]# innobackupex --user=root --password=123 --apply-log /backup/full将数据目录准备为空的,并且数据库实例是关闭的,进行数据恢复[root@db01 mysql]# innobackupex --copy-back /backup/full增量备份[root@db01 ~]# innobackupex --user=root --password=123 --no-timestamp --incremental --incremental-basedir=/backup/full/ /backup/inc1